Within the last weeks, I thought about building a service for automatically answering incoming user questions by using a repository of previously answered questions.
The benefit of such an automatic answering system is obvious, but as a foundation for that implementation, a trained text association model is needed.
A large corpus of existing texts therefore is used to learn semantic associations of individual words within all given sentences. Each of the trained words is then represented as a vector. Those vectors are then used to calculate the distance of individual words. This trained repository of word vectors is called a word embedding and can be used to detect similarity of texts.
The given training text corpus decides on how good a trained word embedding works for a specific domain. Let’s say you train a model by using all episode texts of the Simpsons, it will work perfectly for texts containing Simpson related statements, while it will not work at all for classifying medical texts.
Where to find a training text corpus?
An essential part of training a word embedding is to find enough high quality texts within a given domain to train a high quality model.
An obvious way of finding texts of a given domain is to scrape all visual texts from one or more given Web URLs.
Let’s say we want to train a word embedding on financial business and stock investing, we would scrape all visual texts from The Wall Street Journal.
Another example is to use a free online ebook from Project Gutenberg, e.g.: Jane Austen’s book ‘Pride and Prejudice‘ to train the model.
Scraping the Web
Scraping a Web page and crawling to all embedded links recursively is pretty simple. In my Streamlit data app I used the Python library BeautifulSoup to extract all links and all visual texts within a given page.
A config for the maximum number of links to follow per page reduces the overall number of crawled links to not explode in terms of scraped follow up pages.
Most of the time, a follow up link does not lead to a page talking about the same topic but redirects to a completely different domain or even to a social media account.
See below the Streamlit part of the app responsible for scraping a given Web page:
A click on the scrape button starts crawling your given Web link and scrapes all the visual texts from the given Web page.
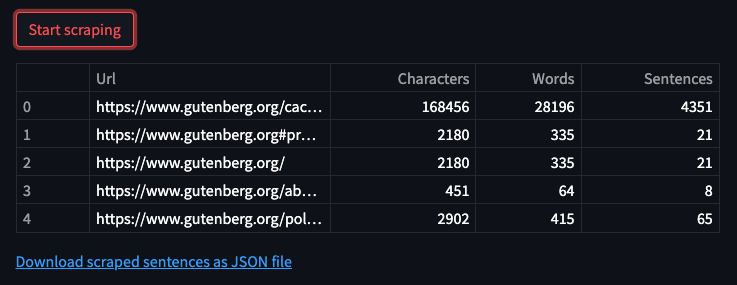
As a result, the Streamlit data app shows a statistic of all the visited pages along with some statistics about how many words, characters and sentences were scraped from that specific url. See below the table of scraping results:
Cleaning the vocabulary
The scraped human readable texts are full of stop words, numbers, dates and special characters. The cleaning step is used to remove all those words from the training vocabulary, as single numbers and single characters deliver no meaning for our word embedding model.
Special handling is implemented for so-called stop words, such as ‘a’, ‘or’, ‘us’, ‘and’ that occur significantly more often in sentences compared to nouns.
The given data-app allows you to remove or to keep those stop words, depending on your use case. By default, stop words are removed from the corpus and therefore to improve the quality of the word embedding.
You can even add additional stop words to refine your trained model.

Training the word embedding
Now that we scraped some texts from the given Web page, we want to start training a word2vec word embedding model.
The vocabulary consists of all unique words of the scraped texts, where their position within all scraped sentences and all the words neighbouring words are used to train a numeric vector.
After training the model, those numeric vectors can be used to check the similarity and the logic distance between any given word within the model.
The larger the trained word vector is, the more information it can transport, but it also increases the size of the model.
See below the vector size and training epochs used to train our word embedding model:
After the training is finished, you can download the packaged model for further use in your own AI enhanced service, such as my automatic support question responder.
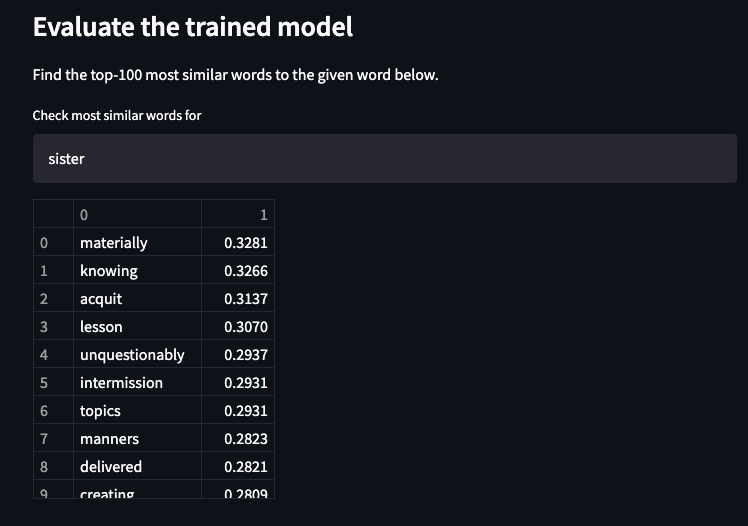
Evaluating the model
Now that we have a trained model, we can challenge the model by requesting a list of the most similar words for any given word. In case of our scraped text above, we will check what are the most similar words for ‘sister’. As we trained the model from the full novel texts of Jane Austen’s ‘Pride and Prejudice’, it seems that the model did fully grasp the materialistic character of Elizabeth’s sister 🙂
Summary
Scraping texts from given Web pages is a great way to train an AI word embeddings model in case you don’t already own a large corpus of training sentences.
By offering an out-of-the-box Streamlit data app for scraping and cleaning Web texts from given Urls, you can easily start to test if a given Web page contains enough sentences to train a good word embedding model without spending much programming effort.
Visit and test the Streamlit data app here and find it’s source code for your further use on GitHub.
If you find my app interesting, please spread the word and share the app.
