A semantic cache for large language model (LLM) based applications introduces a plethora of advantages that revolutionize their performance and usability.
Primarily, it significantly enhances processing speed and responsiveness by storing precomputed representations of frequently used language elements.
This minimizes the need for repetitive computations, leading to quicker response times and reduced latency, thereby optimizing the overall user experience. Moreover, semantic caching plays a pivotal role in resource optimization, mitigating the computational load on underlying hardware. This not only enhances operational efficiency but also contributes to cost-effectiveness in terms of infrastructure utilization.
The preservation of contextual information is another key benefit of semantic caching, particularly valuable in natural language processing applications.
By retaining precomputed semantic representations, the cache ensures a more nuanced and contextually aware understanding of language constructs, leading to more coherent and contextually relevant responses. Furthermore, semantic caching facilitates scalability by reducing the strain on computational resources, allowing LLM-based applications to handle larger workloads seamlessly without compromising performance.
In essence, the implementation of a semantic cache emerges as a strategic enhancement, offering improved speed, resource efficiency, contextual understanding, and scalability for large language model-based applications.
Vector Databases as Semantic Cache
Leveraging cutting-edge vector databases, such as Weaviate, Chroma, or Pinecone, as a semantic cache represents a revolutionary stride in optimizing information retrieval for modern applications.
These databases excel in storing and processing complex, high-dimensional data, making them ideal candidates for enhancing the efficiency of semantic caching.
By representing textual objects as vectors and employing advanced indexing techniques, these databases streamline the retrieval of semantic information, significantly reducing latency and boosting overall system performance.
Weaviate, with its graph-based architecture, Chroma’s versatility in handling multi-modal data, and Pinecone’s focus on similarity searches, offer tailored solutions to diverse semantic caching needs.
Implementing these vector databases as a semantic cache not only ensures rapid and accurate information retrieval but also positions applications at the forefront of technological innovation in the dynamic landscape of data storage and retrieval.
Semantic cached LLM application
The following high-level architectural schema shows how to use a vector database as means of semantically caching application user prompts.
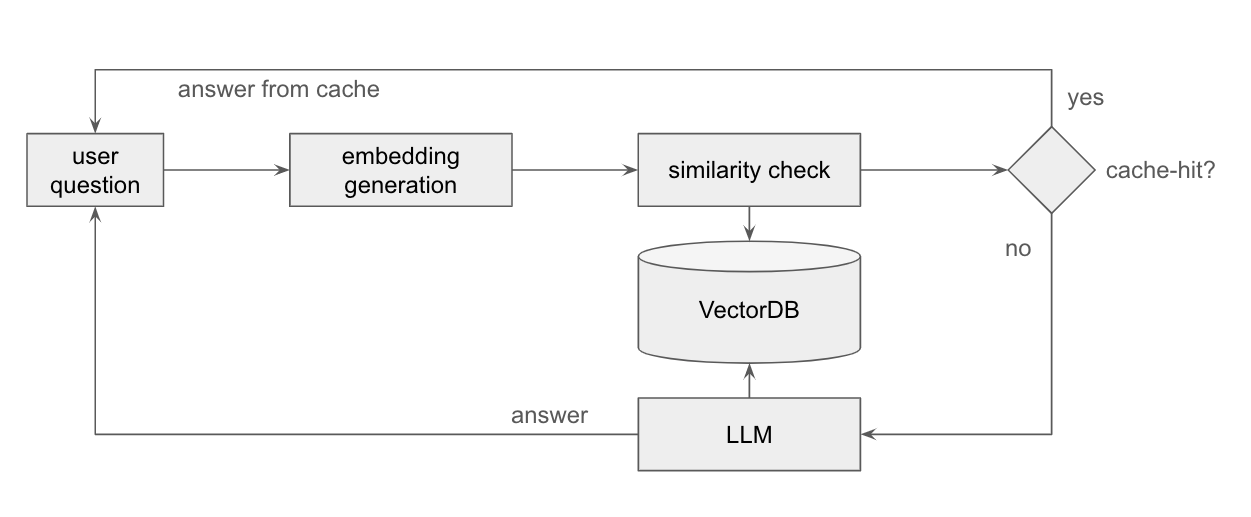
The user’s inquiry undergoes embedding generation, a process converting the input text into an embeddings vector.
This vector is subsequently utilized to query a vector database, such as Weaviate, Pinecone, or Chroma, employing a flexible and swift vector-based similarity index search.
The application designer can set a similarity threshold, determining the level of resemblance that qualifies as a cache hit or rejection.
If the cached database already contains a response to the user’s query, the application promptly retrieves and returns the cached result, bypassing the resource-intensive Large Language Model (LLM) generation.
Conversely, if the user’s question is absent from the cache, the LLM generation process is initiated, yielding the generated answer text, which is not only returned to the user but also stored in the vector database cache under the corresponding prompt text vector embedding for future reference.
This mechanism optimizes response time and resource utilization in applications reliant on semantic caching.
Conclusion
Applications relying on Large Language Models (LLMs) may encounter substantial performance and cost hurdles, particularly when the prompt size escalates, causing cloud costs to rise linearly and latencies to grow exponentially. Employing semantic caches provides a straightforward yet highly effective strategy to mitigate these challenges.
By adopting semantic caches, the token costs associated with LLM-based applications remain low, even as prompt sizes increase, leading to a significant reduction in overall costs. Simultaneously, this approach dramatically enhances application performance, ensuring that response times remain optimized.
In essence, leveraging semantic caches emerges as a practical solution to strike a balance between cost efficiency and performance scalability in the realm of LLM-based applications.