Word embeddings within machine learning and artificial intelligence models are used to analyse the semantic similarity of words within texts and therefore to gain deeper knowledge during sentient text analysis and classification.
Word embeddings represent pre-trained databases of a given vocabulary where each word comes with a unique numeric vector that represents its position within a multidimensional space. This position is used to measure the distance of one word to other words within the vocabulary. The distance as similarity measurement between words is then used to classify and label given texts, to identify similar texts or to detect if texts contain toxic or abusive language.
Word embeddings are the state-of-the-art technology within the artificial intelligence community to analyse and classify texts and to identify their sentient.
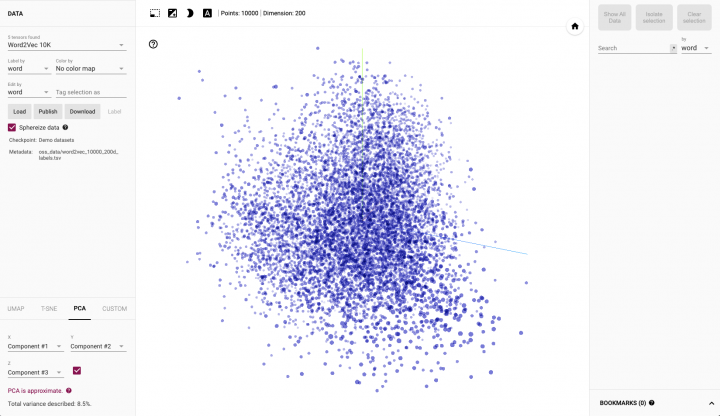
While writing my book about machine-learning and neural networks with TensorFlow 2 and Keras, I came across a really nice tool that is used to visualise word embeddings within 3 dimensional space, which is the TensorFlow word projector.
See within the video below, how the word projector is used to visualise ten thousands of words within a given vocabulary within interactive 3 dimensional space.
It is a great way of reviewing if your own trained word embedding contains the necessary amount of words and also if the corpus of your vocabulary is correct.
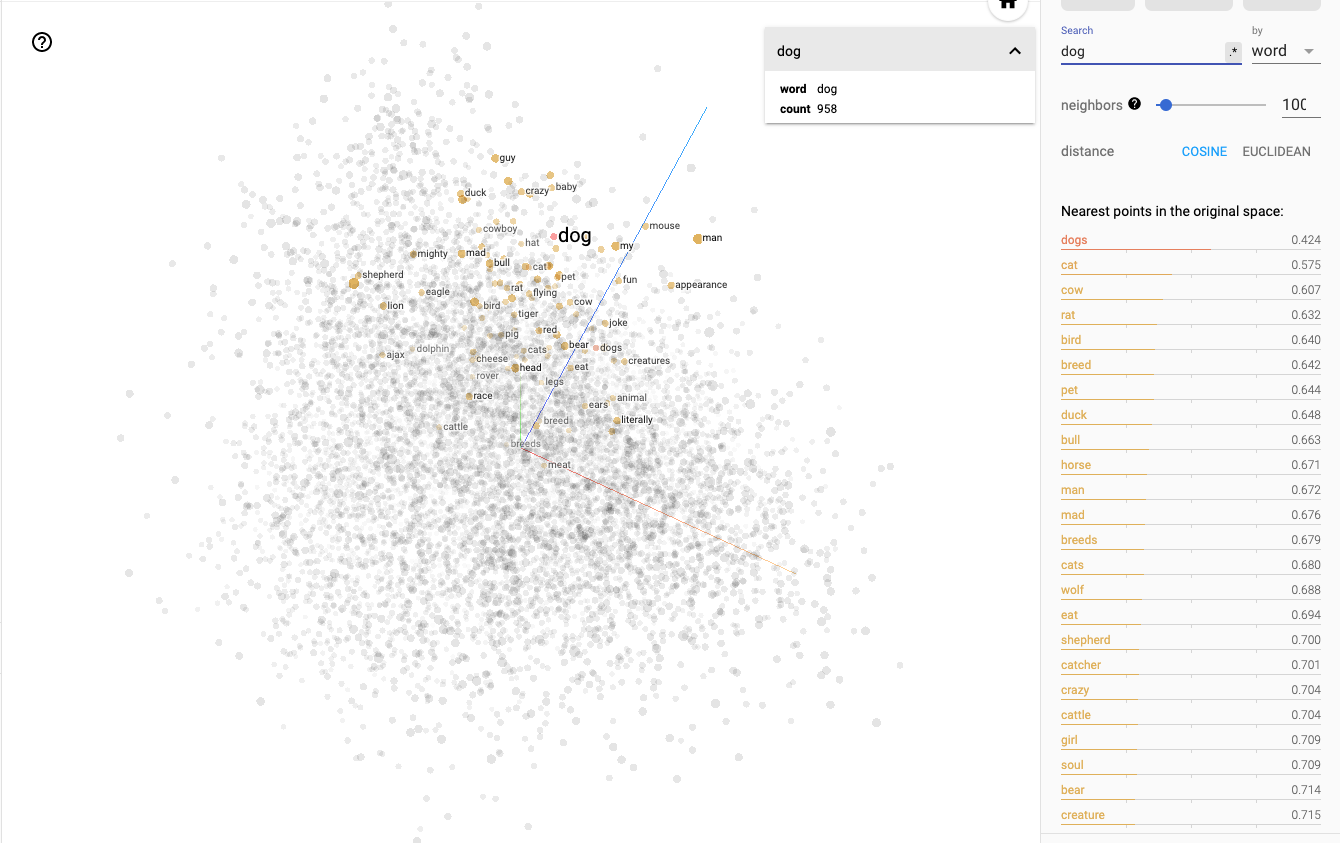
The word embeddings projector also allows you to select individual words, such as the term ‘dog’ and analyse the word’s semantic neighbourhood, as it is shown below: